
摘 要: 運用自組織特征映射神經網絡的工作原理和具體實現算法進行故障診斷分析,在對已有神經網絡聚類分析方法概括和總結的基礎上,結合實驗數據、仿真數據對自組織特征映射算法故障模型診斷進行研究,得出了有意義的結論。
關鍵詞: 數據挖掘;神經網絡聚類;自組織特征映射;特征提取
實時監測設備運行狀況,在運行參數發生變化時及時報警并提示操作人員進行檢查,對于保障設備的正常運行具有重要的意義。傳統的故障診斷方法一般都是采用基于知識的故障診斷系統,以領域專家和操作人員的啟發性主觀經驗知識為基礎,經過產生式推理和演繹推理來獲得大量的規則,從而獲得診斷故障原因和部位。但由于基于知識的故障診斷系統不具有學習功能,知識的獲取途徑只有通過專家或操作人員總結經驗獲取,從而制約了其進一步的發展[1,2]。
神經網絡是模擬人腦結構開發的一種并行運算的數字算法,由輸入層、輸出層和隱層組成,可以用來建立輸入輸出之間復雜的映射關系。由于具有良好的記憶聯想功能,因此在故障診斷領域得到了廣泛的應用。但是傳統BP神經網絡只能用于確定性關系的學習,不能處理矛盾樣本,而故障診斷系統中的數據有些具有一定的離散性,因此需要將輸入層的確定性信息模糊化之后變成模糊量,將傳統神經網絡變為模糊神經網絡,將與故障運行參數相對應的隸屬度數值作為輸入,從而使神經網絡系統更加適合設備故障狀態的描述。
1 自組織映射算法
1.1 拓撲機構與權值調整
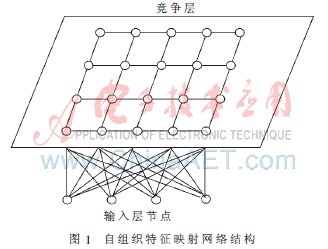
1981年KOHONEN T教授提出一種自組織特征映射SOFM(Self-Organizing Feature Map),又稱為SOM網或Kohonen網。他認為當一個神經網絡接受外界輸入模式時將會分為不同的對應區域,各區域對輸入模式具有不同的響應特征。SOFM網共兩層,輸入層模擬感知外界輸入信息的視網膜 ,輸出層模擬做出響應的大腦皮層。輸入層各神經元通過權向量將外界信息匯集到輸出層的各神經元。輸出層屬于競爭層,神經元的排列有多種形式,如一維線陣、二維平面陣和三維刪格陣。輸出按照二維平面組織是SOFM網最典型的組織方式,結構如圖1所示。SOFM網采用的學習算法是在“勝者為王”算法基礎上改進的,主要區別在于調整權向量與側抑制的方式不同。SOFM學習算法中不僅獲勝神經元本身要調整權向量,其周圍的神經元在其影響下也要不同程度地調整權向量。權向量的調整函數稱為墨西哥帽函數。由于該函數的復雜性,在實際中采用較為簡化的大禮帽函數或廚師帽函數來處理。

(6)結束檢查。訓練結束是以學習率?濁(t)是否衰減到0或某個預定的正小數為條件,不滿足條件則回到步驟(2)[3,4]。
2 自組織映射算法在故障診斷中的處理
2.1 理論依據
任何聚類算法的參數對聚類結果都具有直接的影響,當考慮高維數據的時候,合理的降維是一個很重要的方面,降維應該遵循一定的方法。在算法中處理高維數據時將更高維密集單元的搜索限制在子空間密集單元的交集中,這種候選空間的確定采用基于關聯規則挖掘中的先驗性質,該性質在所有空間中利用數據項的先驗知識以裁減空間。采用的性質是:如果數據在k維單元是密集的,則它在k-1維空間上的投影也是密集的。也就是說,給定一個k維的候選密集單元,檢查它的k-1維投影單元,如果發現任何一個不是密集的,則知道第k維的單元也不是密集的[5]。由此進一步得出結論,如果聚類的某一維是密集的,則它對于整個k維聚類也是可用的,否則,在整個k維數據聚類中不起作用。把這一關聯規則挖掘中的性質應用到故障特征屬性的降維中。
SOFM的數據壓縮和特征抽取的功能,將高維空間的樣本在保持拓撲結構不變的條件下投影到低維空間,在高維空間中很多模式的分布具有復雜特性,但當映射到低維空間后,由于維度和節點數量(從多維對象映像到二維的神經網絡節點)的降低,其規律很明顯。
2.2 算法
2.2.1 預處理:選擇合適的維參與映射
自組織特征映射網絡聚類是模型聚類的一種,其自組織學習過程也可以描述為:對于每一個網絡的輸入,只調整一部分權值,使權向量更接近或更偏離輸入矢量,這一調整過程,就是競爭學習。隨著不斷學習,所有權向量都在輸入矢量空間相互分離,形成了各自代表輸入空間的一類模式,這就是自組織映射網絡的特征自動識別的聚類功能。每個故障模式參數樣本作為聚類的一個“典型”,可以根據新對象與哪個參數樣本最相似(基于某種距離計算方法)而將其分派到相應的聚類中。被診斷設備狀態可以由一系列的特征參數來描述,一旦設備出現某個故障或多個故障,其狀態特征參數也會發生相應的變化。因而,特定的特征參數值反映了相應的設備故障。在故障診斷領域,當設備處于故障狀態時,將特征參數呈現出的特定取值稱之為故障征兆,即不同的故障征兆對應著不同的故障類型;通常,設備的故障類型不止一種,因此用故障域來表述設備可能出現的多種故障類型,用征兆域來表述可能出現的多種故障征兆。由此可見,可以認為故障診斷即進行由征兆域到故障域的模式識別,或是由征兆域到故障模式的具有聯想能力的判別分類[6-8]。
需要指出的是,文本型數據轉換以后應該作為分類數據來處理。一般,在聚類過程中,如果分類維和密集維表示的是非空間屬性中不同特征的某個方面,包括太密集的數據或者太分散的數據,都不適合進入聚類,如果不是作為分類數據,則太集中的數據不會對聚類產生影響,只會增加處理的時間。而太分散的數據會對聚類結果產生不良的影響。但是對于表示同一特征的不同維來說,有些維是密集的,有些維不是密集的,因此需要在這些維中選擇合適的維進行聚類。
2.2.2 診斷實例
在故障診斷分析應用中,用戶應該根據聚類的目的先選擇一些候選維,準備參與聚類。取X1~X10 作為征兆參數,在系統中各自參數點具有不同特點,在發生可能的故障時,它們的變化范圍和方向各不相同,對征兆參數進行歸一化處理,如表1所示。

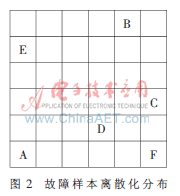
應用自組織特征映射網絡來模擬模糊聚類故障診斷的全過程,應用Matlab工具箱進行編程,根據故障樣本,利用newsom創建網絡的競爭層為6×6的結構,網絡結構是可以調整的,可以根據數據規模進行調整,然后輸入樣本p(如表1參數值進行訓練),利用函數train和函數sim對網絡進行訓練,并對故障樣本進行模糊聚類。由于訓練步數大小影響著網絡的聚類性能,分別設置100、200和500步對網絡進行訓練,觀察性能[7,8];選用聚類效果較好的訓練步數為500步的網絡,利用自組織特征映射網絡選取聚類數目為6類,應用訓練數據對網絡進行訓練,保存網絡參數的訓練結果,以及訓練數據的離散結果,然后利用訓練后的網絡對測試數據進行離散化處理,即可得到離散化結果,如圖2所示,可見6種故障模式分別占據不同區域,可作為故障診斷故障基準。
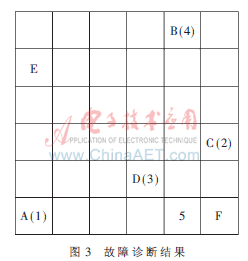
競爭層輸出的不同的神經元代表了不同的故障類型,系統某種故障與標準樣本的故障類型越相似,在競爭層上的興奮神經元的幾何位置也就越接近。模擬某電子設備的典型故障,試驗中選取了5個故障樣本,經模糊量化后得到待檢故障模式,如表2所示。

將其輸入到已訓練好的SOFM神經網絡,在競爭層中出現了圖3的分類結果。第1組故障樣本輸出的幾何距離Di最接近故障形式A,表明該故障形式為末級組件電路故障;同理,可判斷第2組故障樣本的故障形式為激勵產生故障;第3組和第4組故障樣本的輸出分別與D和B的位置重合,表明第3組和第4組故障樣本的故障形式分別為PIN開關故障和前級組件電路故障;第5組故障樣本的輸出最接近F,表明該故障形式可能為饋線故障。診斷結果與仿真機模擬的故障一致。
模糊聚類分析是依據客觀事物間的特征、親疏程度和相似性,通過建立模糊相似關系,對客觀事物進行分類的數學方法。用模糊聚類分析方法處理帶有模糊性的聚類問題更客觀、靈活和直觀,且計算更加簡便。實踐表明,它突破了常規邏輯推理方法的局限,在很少先驗知識的情況下,能快速而準確地解決故障診斷問題。
參考文獻
[1] 楊軍,馮振聲,黃考利,等.裝備智能故障診斷技術[M]. 北京:國防工業出版社,2004:119-122.
[2] 何青,張海巖,張志.基于C8051F的便攜式多通道數據采集系統[J].儀器儀表學報,2006,27(6):140-141.
[3] WANG X,ILTON H.DBRS:a density based spatial clustering method with random sampling[C].Proceedings of the 7th PAKDD.Seoul,Korea,2003:563-575.
[4] TROST B,L IANG M.Mechanical fault detection using fuzzy index fusion[J].International Journal of Machine Tools & Manufacture,2007(47):1702-1714.
[5] CZESLAW T K,TERESA O K.Neural networks application for induction motor faults diagnosis[J].Mathematics and Computers in Simulation,2003(63):435-448.
[6] 程昌銀,李琳.模糊神經網絡故障診斷研究[J].武漢理工大學學報,2002,24(1):220-225.
[7] 羅志勇.雷達系統智能故障診斷技術研究[D].西安:西北工業大學,2006.
[8] PAKKANEN J.The evolving tree,a new kind of self-organizing neural network[C].Proceedings of the Workshop on Self-Organizing Maps,Kitakyushu,Japan,2003:311-316.