
摘 要: 數(shù)據(jù)挖掘的一個重要分支是數(shù)據(jù)流聚類技術(shù)。基于K均值算法的基礎(chǔ)提出了CluTA算法。該算法在處理用K均值方法分類得到的結(jié)果時考慮時間衰減因素和相似簇的合并,達(dá)到用戶對時間的要求并實(shí)現(xiàn)了任意形狀簇聚類。理論分析和實(shí)驗(yàn)結(jié)果都表明算法具有可行性。
關(guān)鍵詞: 數(shù)據(jù)流;密度聚類;均值關(guān)鍵點(diǎn);時間衰減
數(shù)據(jù)流是指連續(xù)的、潛在無限量的、快速變化的、隨時間而至的數(shù)據(jù)元素的流。由于數(shù)據(jù)采集的快捷化和自動化,數(shù)據(jù)庫技術(shù)和互聯(lián)網(wǎng)技術(shù)的飛速發(fā)展,日常生活已經(jīng)與數(shù)據(jù)流息息相關(guān),如網(wǎng)絡(luò)實(shí)時監(jiān)控、電子商務(wù)、衛(wèi)星遙感等。這些數(shù)據(jù)都具有流的特性。而傳統(tǒng)的數(shù)據(jù)挖掘方法需多遍掃描全部數(shù)據(jù)且數(shù)據(jù)必須以靜態(tài)形式存儲在磁盤空間里,因此用來專門處理數(shù)據(jù)流的數(shù)據(jù)處理模型和算法應(yīng)運(yùn)而生[1]。
CluStream算法是經(jīng)典數(shù)據(jù)流聚類和主要算法,該算法提供了一個解決數(shù)據(jù)流聚類問題的優(yōu)秀雙層聚類方法,但由于它采用的是基于BIRCH算法的核心思想,所以僅限于得到球形聚簇結(jié)果[2]。K均值算法是基于劃分的聚類方法,采用分而治之的策略對數(shù)據(jù)分塊后再進(jìn)行聚類,這樣保證算法在較小的內(nèi)存空間范圍內(nèi)獲取常數(shù)因子的近似結(jié)果[3]。該算法的缺點(diǎn)是K取值的不確定因素太多,影響了準(zhǔn)確性且不能考慮被分析數(shù)據(jù)的時間相關(guān)性。
1 基于時間衰減和簇合并的聚類處理算法(CluTA)
在分析某些類數(shù)據(jù)時往往更加注重其近期變化帶來的影響,時間越久遠(yuǎn)被關(guān)注的程度就越低,如網(wǎng)絡(luò)入侵行為的分類和趨勢、股市不斷變化的大盤信息等。為提高聚類得到結(jié)果的精確性,在挖掘時需考慮時間衰減的因素。由于K均值算法聚類的結(jié)果都是球型簇,本文通過合并相近相似簇達(dá)到輸出任意形狀簇的聚類結(jié)果。
本算法采用分層思想,第一層增加K均值算法得到中心點(diǎn)的信息,使每個中心點(diǎn)c中保留s(簇內(nèi)所有的點(diǎn)到c的距離和)、d(簇內(nèi)最遠(yuǎn)點(diǎn)到c的距離)、n(簇內(nèi)所有點(diǎn)的個數(shù))、t(c的生成時刻)。第二層結(jié)合本算法給出的衰減函數(shù)和密度計(jì)算出關(guān)鍵點(diǎn)的權(quán)重;比較關(guān)鍵點(diǎn)的權(quán)重和距離,如果距離足夠近且權(quán)重比在允許范圍內(nèi)則合并簇。重復(fù)循環(huán)直到?jīng)]有可合并的簇,輸出最終結(jié)果。
1.1 相關(guān)定義和性質(zhì)
假設(shè)數(shù)據(jù)以塊X1,X2,…,Xn,…的形式按序到達(dá),每個塊內(nèi)包含m個數(shù)據(jù)點(diǎn)xi(xi1,xi2,…,xim)且可以在內(nèi)存中進(jìn)行處理。每個數(shù)據(jù)點(diǎn)是一個d維向量。CluTA算法是以Kmeans為基礎(chǔ)初次聚類生成k個關(guān)鍵點(diǎn),采用五元組的方式存儲關(guān)鍵點(diǎn)信息。
定義1. 關(guān)鍵點(diǎn)
采用Kmeans方法對在t時刻到達(dá)內(nèi)存的數(shù)據(jù)塊Xt進(jìn)行聚類得到k個關(guān)鍵點(diǎn),關(guān)鍵點(diǎn)ri是五元組的形式,

上述(1)表示兩簇的均值點(diǎn)距離小于或等于兩簇內(nèi)最遠(yuǎn)距離之和,相距足夠近則考慮合并簇。但也可能出現(xiàn)兩簇相距很近仍不符合合并要求的情況。如圖1所示,兩簇的距離足夠近,但二者密度相差較大就不應(yīng)該再合并。因此加上條件(2),通過計(jì)算兩簇的權(quán)重比是否相差懸殊來決定是否可以合并。若上述限定條件都符合,則合并簇得到如圖2所示結(jié)果。


1.3 算法分析
該算法改進(jìn)K均值聚類算法結(jié)果信息,第一層運(yùn)用K均值算法的計(jì)算復(fù)雜度為O(nkt),n為數(shù)據(jù)點(diǎn)數(shù)目,t為循環(huán)次數(shù),通常有k<<n和t<<n。第二層將生成的k個聚簇進(jìn)行合并,計(jì)算復(fù)雜度為O(k2),k為常數(shù)級關(guān)鍵點(diǎn)數(shù)目。在K均值的基礎(chǔ)上增加的內(nèi)存空間也非常少,僅需保存k個關(guān)鍵點(diǎn)和一些中間變量。因此,該算法在時間和空間復(fù)雜度上都近似于K均值聚類算法,具有簡單、高效的特點(diǎn)。
2 實(shí)驗(yàn)分析
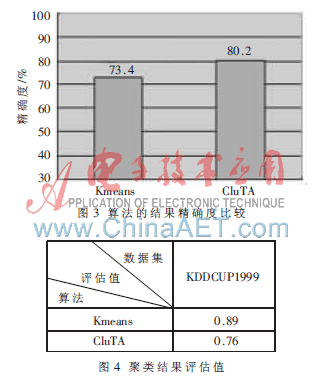
算法在VC 6.0環(huán)境下采用C編寫,實(shí)驗(yàn)平臺為一臺CPU 2.8 GHz、內(nèi)存1 GB、操作系統(tǒng)為Windows XP的PC機(jī)。采用了UCI的KDD CUP 1999網(wǎng)絡(luò)入侵檢測數(shù)據(jù)集。KDD CUP 1999數(shù)據(jù)集共23類,每一數(shù)據(jù)有42個屬性,去除一些非數(shù)值型數(shù)據(jù)的維數(shù),選留其中的20維做為實(shí)驗(yàn)數(shù)據(jù)。使用每類中的5 000條中的20個屬性,打開文件模擬數(shù)據(jù)流環(huán)境讀入數(shù)據(jù),用Kmeans算法得出初始聚類關(guān)鍵點(diǎn)信息,再運(yùn)用CluTA算法進(jìn)行簇合并,最終與僅用Kmeans算法聚類的結(jié)果精確度比較,如圖3所示,判斷聚類質(zhì)量的算法可參考文獻(xiàn)[5]。聚類質(zhì)量為類內(nèi)距離值加上類間密度值。類內(nèi)距離是表示該類內(nèi)部點(diǎn)的密疏程度,類間密度是衡量各個類的平均密度關(guān)系,如圖4所示,該值較小表明聚類簇集的類間區(qū)分度較好,因此二者總和越小,表示聚類質(zhì)量越好。
為解決使用價值隨時間衰減的一類流數(shù)據(jù)聚類問題和實(shí)現(xiàn)任意形狀簇的聚類,本文在基于傳統(tǒng)的K均值聚類算法基礎(chǔ)上,保留其直觀、高效的特點(diǎn),提出了基于時間衰減的任意簇?cái)?shù)據(jù)流聚類算法。即在K均值算法處理得到結(jié)果的基礎(chǔ)上再考慮用時間和密度、空間距離等因素合并簇。理論分析和實(shí)驗(yàn)結(jié)果證明該算法相對于僅用K均值算法在處理對近期價值比較關(guān)心一類的數(shù)據(jù)時具有更精確的聚類結(jié)果。下一步的工作將著重于提高算法的效率和將其應(yīng)用到更廣泛的生活實(shí)踐中。
參考文獻(xiàn)
[1] Han Jiawei. Micheline. Data Mining:Concepts and Techniques, Second Edition[M].China Machine Press,2008.
[2] AGGARWAL C C, et al. A framework for clustering evolving data streams.In:Proc.of the 29th VLDB Conf.,2003.
[3] GUHA S,MISHRA N,MOTWANI R. Clustering data streams[C].Proceedings of the Annual Symposium on Foundations of Computer Science.2000.
[4] 倪巍偉,陸介平,陳耿,等.基于k均值分區(qū)的流數(shù)據(jù)高效密度聚類算法[J].小型微型計(jì)算機(jī)系統(tǒng),2007,28(1):83-87.
[5] HALKIDI M, VAZIRGIANNIS M. Clustering validity assessment;finding the optimal partitioning of adata set[C]. ICDM 2001:187-194.