
摘 要:傳統的遺傳算法存在早熟收斂和易于陷入局部搜索最優等缺陷;根據關聯規則挖掘的要求和特點,提出一種應用于關聯規則挖掘的自適應小生境遺傳算法。
關鍵詞:關聯規則;自適應小生境遺傳算法;選擇;雜交
?
遺傳算法(GA)是一種基于生物界適者生存理論的自適應搜索技術,其主要特點是群體搜索策略和群體中個體之間的信息交換,算法的搜索過程不依賴于目標函數的梯度信息[1-4],目前它已經成功地應用于組合優化、自動控制等眾多領域[5-6]。由于基本遺傳算法所具有的特性,用它進行優化時的結果將使群體中的個體集中到目標函數值最大的一個峰值上,存在局部搜索能力不強,易陷入局部最優和早熟等缺陷,使得傳統的GA在進行查詢優化時效果不理想。在實際應用中有時希望最終搜索到的優化點不是只在一個峰值上,而是在多個峰值上都有分布,而且分布的多少與峰值的高低成正比。這就要求種群保持一定的個體多樣性。這點在基于遺傳的機器學習等問題中也尤為重要[2]。數據挖掘技術是機器學習、人工智能、數據系統等領域的研究方向。數據挖掘就是從大型數據庫的大量原始數據中提取出人們感興趣的、具有潛在應用價值的指示和信息。其中關聯規則是最有用的信息之一,它用于發現大量數據項集合之間的關聯[7]。本文提出一種自適應小生境遺傳算法應用于關聯規則挖掘技術。
1 關聯規則的描述
令I = {i1,i2 , ... ,id}是事務中所有項目的集合,而T={t1 , t2, ... , tn }是所有事務的集合。每個事務ti包含的項集都是I的子集。在關聯分析中,包含0個或多個項的集合被稱為項集。關聯規則(Association Rule)是形如X→Y的蘊涵表達式,其中X和Y是互不相交的項集。關聯規則可以用它的支持度(support)和可信度(confidence)度量。支持度確定規則中給定數據集的頻繁程度,而可信度確定Y在包含X的事務中出現的頻繁程度。給定事務的集合T,關聯規則發現是指找出支持度大于等于minsup并且可信度大于minconf的所有規則,其中minsup和minconf是對應的支持度和可信度閾值[8]。研究表明,支持度閾值隨著項集長度的增加而遞減,因此用參考文獻[9]針對支持度閾值設置懲罰函數可表示為:
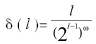
其中 l為相繼長度,ω= ( 0,1]。
2 自適應小生境遺傳算法原理
2.1 小生境技術的生物學基礎
在自然界,“物以類聚,人以群分”的小生境現象普遍存在,生物總是喜歡同自己形狀、習性相似的生物在一起,并與同類交配繁衍后代,在生物學中,把某種特定環境及其在此環境中生存的組織稱為小生境。小生境的形成在生物學上有著積極的意義,為新物種的形成提供了可能性[6]。
在具體的工程應用中,小生境技術演變為:將每一代個體劃分為若干類,每個類中選出若干適應度較大的個體作為一個類的優秀代表組成一個種群,再在該種群與不同種群之間通過雜交、變異產生新一代個體群,同時采用預選擇機制、排擠機制或共享機制完成選擇操作。也就是說讓個體在一個特定的生存環境中進化,形成多個小生境,最終達到小生境內的峰值,從而找到全局最優解。受此啟發,近年來人們將小生境現象引入到遺傳算法中,實踐證明,這一技術對于改善遺傳算法全局收斂性能具有良好的效果[10]。
2.2 自適應小生境遺傳算法原理
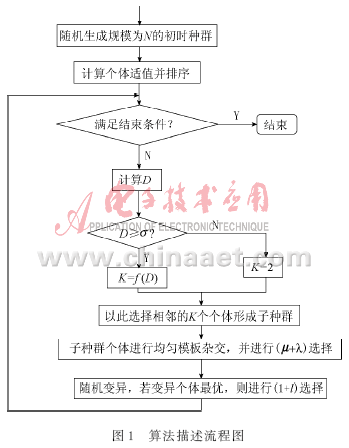
為解決傳統遺傳算法種群多樣性低的問題,自適應小生境遺傳算法提出:首先將初時種群中的個體按適值排序,然后相似的若干個體進入一個小生境即子種群中獨立進化。子種群的規模是隨著大種群的多樣性的變化而自適應變化的。設大種群的規模為N,子種群規模為K,則有:?????

其中,D是大種群個體的方差,f(D)是關于D的一個函數,可根據問題的特征預先設置;σ為一常數。
當大種群個體多樣性降低時,D就減小,當D小于某一閾值σ時,子種群規模K降低到最低限度2。
在小生境技術中,插用(μ+λ)選擇機制,它被認為是集中流行進化算法的選擇機制中選擇率最高的一種。交叉操作采用均勻模板交叉算子。當交叉結束后,立即進入(μ+λ)選擇,以生成子種群的新一代個體。
新產生的個體進行隨機變異,當變異的個體為子種群中的最佳個體時,應該對該最佳個體及其變異所得到的新個體進行(1+ l)選擇,以保證最優個體以概率 l保留到下一代[11]。
算法描述如圖1所示。
?
3 試驗分析
3.1 數據庫設計
采用某腫瘤醫院的數據庫進行試驗。數據庫中記錄了從1994年~2003年2 600多例腫瘤患者的病歷,抽取出病歷中的重要信息,構成數據表,如表1所示。

?
3.2? 數據庫數字化
為了易于表示起見,將數據庫中重要字段取值數字化。
腫瘤種類劃分:肺癌;胃癌;乳腺癌;大腸癌;口腔癌;肝癌;宮頸癌;食管癌;其他。
診療計劃劃分:手術;放療;化療;生物免疫治療;中醫中藥治療。
治療效果:治愈(5年存活);好轉;惡化;死亡;自動出院。
國際分期劃分:1(I);2(IIa);3(IIb);4(III),5(IV)。
3.3 關聯規則的提取
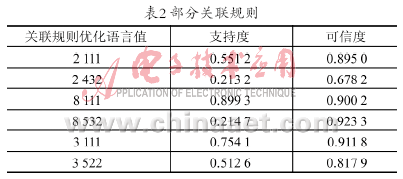
為挖掘數據庫中蘊涵數字化屬性間的關聯規則,根據以上數字化步驟,將4個屬性分別劃分為9、5、5、5個屬性等級。設X={腫瘤種類、國際分期},Y={診療方案、治療效果},給定最小支持度和最小置信度都為0.02,表2列出部分有意義的所得到的優化語言值關聯規則。
?
根據關聯規則的特點和要求,提出了基于自適應小生境遺傳算法的關聯規則挖掘算法。試驗顯示,該方法快速有效。
參考文獻
[1]?RUDOLPH? G.Convergence analysis of canonical genertic algorithme[J].IEEE Trans on Neural Network,1994,5(1) :96-101.
[2]?田盛豐.人工智能原理與應用[M].北京:北京立功大學出版社,1993.
[3]?FOGEL.An introduction to simulated evolutuionary ptionization[J]. IEEE Trans on Neural Network,1994,5(1): 3-14.
[4]?陳國良.遺傳算法及其應用[M].北京:人民郵電出版社,1996.
[5]?SONG? S? K,GORLA? N. Agenetic algorithm for vertical fragmentation and access path selection[J].The Computer Journal,2000,43(1):81-92.
[6]?JACK? L? B,NANDI? A? K. Genetic algorithms for feature selection in machine condition monitoring with vibration signals[J].IEEE Proceedings Vision,Image and Signal Processing,2000,47(3):205-212.
[7]?TAN Ping? Ning ,STEINBACH M,KUMAR V.數據挖掘導論[M].北京:人民郵電出版社,2006.
[8]?潘舒,吳陳.基于遺傳算法的關聯規則挖掘[J].現代電子技術, 2008,265(2):90-92.
[9]?趙連朋,金喜子,孫亮,等.基于小生境遺傳算法的關聯規則挖掘方法[J] .計算機工程,2008,34(10):163-165.
[10]? 王小平,曹立明.遺傳算法.理論、應用于軟件實現[M].西安: 西安交通大學出版社,2000.
[11]? 郟宣耀,王芳.一種改進的小生境遺傳算法[J].重慶郵電學院 學報(自然科學報),2005(2).