
引言
手勢交互是人機交互領域近年來的研究熱點,特別是利用攝像頭來實現對手勢信息的非接觸性捕獲,并由計算機進行分析理解,然后完成交互任務,由于其自然和符合人自身行為習慣的交互方式而備受青睞。手勢的形態在交互過程中的變化以及周圍環境的干擾都會影響到手勢的識別和理解,因此手勢識別是計算機視覺和人機交互領域中的重要問題,如何將這種交互方式更好地在嵌入式系統中應用更是一個富有挑戰性的工作。
基于視覺的手勢識別過程通常分為四個步驟,即分割、表示、識別和應用。手勢識別算法的關鍵和難點是分割和識別兩個步驟,現有算法在這兩個步驟通常都有計算量大、時間復雜度高的特點,而嵌入式設備又受到資源和計算能力的限制,要能夠做到基于嵌入式系統的實時手勢交互,就有必要對傳統的手勢識別算法進行改進。
本文在單攝像頭條件下,在手勢跟蹤的相關工作基礎上,提出了一種基于手勢結構特征的手勢識別方法,使之滿足嵌入式系統中的人機交互對實時性、準確性及連續性的要求。本文使用了計算量小且性能高的Camshift算法作為跟蹤算法,并將其跟蹤結果作為手勢識別的參考因子,這樣可以大大減少手勢識別的工作量;手勢的識別則采用了手勢跟蹤結果與手勢形態結構特征相結合的處理方法。將手勢跟蹤的結果作為參考因子,可以除去圖像中與手勢無關的背景圖像,利用手勢形態結構特征使得手勢識別工作不是對手勢邊緣的每個點進行處理,轉而對手勢的外接多邊形進行處理。這兩種方法相結合不僅使識別工作的計算量大大降低,對手勢識別的精確度也有所提高,而且不需要對各種手勢進行訓練就可以完成識別工作,使得識別更加方便和簡潔。
1相關工作
關于手勢識別的算法,國內外的研究人員已經提出了很多不同的解決方案。目前比較常用的有基于統計的HMM模型、基于遺傳算法以及基于人工神經網絡的手勢識別等。基于統計的HMM方法,其優點是利用先驗知識建立視覺特征之間的因果關系來處理視頻處理中固有的不確定性問題,不但能夠在每個時刻上對多個隨機變量所對應的不同特征之間的依存關系進行概率建模,而且考慮了各個時刻間的轉移概率,能夠很好地反映特征之間的時序關系。但是它需要維護一個具有一定規模的樣本庫,而且在使用HMM進行手勢識別時計算量大。當然,樣本庫的規模越大其分布越接近實際情況,手勢識別的準確率就越高,而且還需要使用數據平滑的技術來擴大小概率的值。遺傳算法對圖像進行離散化處理,對圖像離散點進行控制,把圖像識別問題轉換為一系列離散點的組合優化問題;但它不能夠及時利用網絡的反饋信息,搜索速度比較慢,所需訓練樣本大、訓練時間長。人工神經網絡通過把大量的簡單處理單元(神經元)廣泛地連接起來構成一種復雜的信息處理網絡,它在不同程度和層次上模仿人腦神經系統的信息處理、存儲和檢索功能,需要的樣本少、效率高;但是需要人的參與訓練,識別的正確率受主觀因素的影響。
總體來說,在人機交互系統中,手勢的跟蹤與識別應該滿足以下幾個要求:
a)實時性好,避免對高維度特征矢量的計算,數據量大的數組處理以及復雜的搜索過程。
b)足夠的魯棒性。不受識別對象旋轉、平移和比例改變以及攝像頭視角改變的影響。
c)手勢跟蹤的連續性和自動初始化,能夠在跟蹤失敗后自動恢復跟蹤,盡量減少人的干預。
本文提出手勢識別和跟蹤方法不再追隨傳統的將識別的四個步驟孤立起來,而是將手勢跟蹤的結果與手勢的識別這兩個獨立的步驟聯系起來,將跟蹤得到的手勢預測的區域設為下一幀圖像識別的感興趣區域(regionofinteresting,ROI);基于Camshift算法,根據前一幀手勢在圖像中的位置和顏色信息,對手勢在下一幀圖片所處的位置進行預測,主要是基于顏色的統計信息。它運算量小,不僅能很好地滿足嵌入式系統的需求,而且跟蹤和預測的效果也非常好。通過對ROI區域進行手勢的分割和識別,可以排除背景圖像對手勢的部分干擾,識別過程的計算量也減小很多。由于每種手勢的邊線都有不同特征,這些不同的特征能很好地反映在手勢的外接多邊形上,因此,可以對不同手勢和外接多邊形建立一個一一映射的關系;通過建立不同手勢的外接多邊形特征庫,對分割出來的手勢作多邊形擬合,只要將提取出來的多邊形與特征庫中的外接多邊形進行匹配就能判斷出手勢的類型。
本文提出的手勢識別方法主要包括三個部分:
a)手勢分割。將手部區域從場景中分割出來,并對手部的區域和輪廓進行提取。這里的手部區域主要根據c)跟蹤的結果提供。
b)手勢圖像的外接多邊形擬合以及匹配部分。對a)提取出來的手勢輪廓作多邊形擬合,分析多邊形的形狀特點,并在特征庫中查找與擬合的多邊形特征相符合的對象,再映射到具體的手勢。
c)手勢跟蹤部分。根據顏色信息對手的區域進行定位,并對圖像進行空間轉換,利用統計原理對下一幀手可能出現的區域進行預測,并將預測的結果反饋給a)的手勢分割部分。
手勢識別流程如圖1所示。
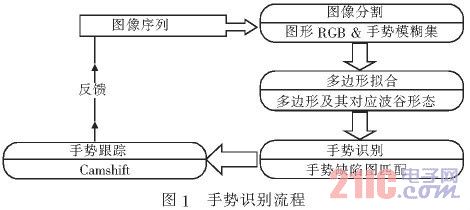
2手勢識別框架
手勢識別主要由靜態手勢的識別和手勢跟蹤兩部分的工作組成,手勢識別框架結構如圖2所示。在本文提出的方法中,采用了將這兩部分的工作進行并行處理的方式,手勢識別的結果傳遞給跟蹤部分,作為跟蹤的對象,并且手勢跟蹤的預測結果反饋給識別部分,將為靜態手勢識別提供ROI圖像區域。這樣不僅能有效地提高跟蹤的高效性,還能提高識別的準確性,將這兩個部分有效地統一起來。

2.1靜態手勢識別
通過靜態手勢的識別,使系統能夠對被跟蹤對象有一個基本的理解,為實現自動跟蹤初始化與跟蹤的自動恢復奠定了基礎。首先,手部區域需要從場景中分割出來。本文采用一種基于模糊集和模糊運算的方法進行手的區域和輪廓提取,通過對視頻流中空域和時域上的背景、運動、膚色等信息執行模糊運算,分割出精確的人手。
靜態手勢的識別是基于輪廓特征的識別,對分割出來的人手作邊緣檢測,得到手勢完整的輪廓邊緣。通過前面的模糊集合運算,能得到圖像的手勢分割的二值圖。兩個具有不同灰度值的相鄰區域之間總存在邊緣。邊緣是灰度值不連續的結果,這種不連續可利用求導方便地檢測出來。
這樣就能得到完整的輪廓邊緣。如圖3所示,左邊為手部區域,右邊為手勢的輪廓。

接下來是對提取的手勢輪廓作外接多邊形擬合。KenjiOka和YoichiSato的指尖搜索方法是首先在一個較大的搜索窗口內掃描確定20個候選指尖位置,然后再對匹配度最大的候選位置周圍的候選進行抑制,同時按一定規則去除位于指尖中間的部分候選。該方法由于需要對搜索區域進行多次逐像素的掃描,造成計算量較大,而且除去手勢中部候選位置的方法的魯棒性較差。文獻[5]給出了通過遍歷手勢輪廓的曲率來進行之間位置搜索的方法,通過對手勢按輪廓順序進行定長掃描的方法,可以找出指尖并做出輪廓線的外接多邊形。但是這種查找方式需要遍歷輪廓線的每個點,而且對每個點還需要作除法運算,這使得算法的計算量太大,而且在搜索指尖時,當受到光線變化使得輪廓線出現很多突起的邊緣時,使得識別工作出現困難。本文提出了一種查找外接邊的搜索方法,通過對手勢輪廓按輪廓點順序進行定長掃描,將手勢輪廓線的外接多邊形擬合出來,同時將滿足定義1的手勢輪廓外接凸邊形缺陷結構設為手勢識別的判斷特征。
2.1.1手勢缺陷圖
定義1手勢缺陷圖是指由手勢輪廓線外接多邊形以及多邊形各條邊所對應的谷底(depthpoint)所組成的特征描述方程。谷底是指外接多邊形的邊與該邊所對應的輪廓線上距離邊最遠的輪廓點。定義手勢缺陷圖的數據結構如下:
TypedefstructCvConvexityDefect{
CvPoint*start;//缺陷開始的輪廓點
CvPoint*end;//缺陷結束的輪廓點
CvPoint*depth_point;//缺陷中距離凸性最遠的輪廓點
Floatdepth;//谷底距離凸性的深度
}CvConvexityDefect;
如圖4所示,手勢輪廓缺陷圖能很好地描述各種手勢,通過對手勢輪廓線外接多邊形的邊數以及邊所對應的谷底深度,可以將手勢缺陷圖映射到不同的手勢。其中A、B、C、D、E、F、G為手勢輪廓線的外接多邊形的各條邊,Da、Db、Dc、Dd、De、Df、Dg為手勢缺陷圖中的谷底到對應邊的深度。
為了得到手勢輪廓缺陷圖,首先必須對手勢輪廓進行多邊形擬合,得出它的外接多邊形。本文提出了一種根據手勢輪廓上相鄰兩點間的凹凸性來進行擬合,通過一次遍歷輪廓上的點,對以下方程進行判定,將適當的點剔除,剩下的點即為外接多邊形的候選定點:
by=nexty-cury(1)
ay×bx-ax×by(2)
ax=pcur.x-pprev.x,ay=pcur.y-pprev.y
bx=pnext.x-pcur.x,by=pnext.y-pcur.y
其中:pcur為當前遍歷的輪廓線上的點;pprev、pnext分別表示當前點的前一個點和后一個點;ax、ay分別為當前點和前一點的x和y坐標值差;bx、by分別為當前點和后一點指尖的x和y坐標值差。
基于輪廓線凹凸形的擬合算法流程如下:
a)將所有的輪廓線上的點按x坐標值大小排序,并找出所有的點中y坐標的最大最小值maxY和minY.
b)將排序后的輪廓點劃分為四部分:首先按照y坐標將輪廓線分為上下兩個部分,將上半部分以maxY所在的x坐標(記為Xmaxy)劃分為兩個部分,分別記為topLeft〈左上〉和topRight〈右上〉;將下半部分以minY所在的x坐標(記為Xminy)劃分為兩個部分,分別記為bottomLeft〈左下〉和bottom-Right〈右下〉。
c)分別對前一步劃分的四個部分(topLeft,topRight,bottomLeft,bottomRight)進行遍歷:對區域topLeft將滿足式(1)<0,式(2)>0的點剔除;對區域TopRight將滿足(1)<0,式(2)<0的點剔除;對區域bottomLeft將滿足式式(1)>0,式(2)>0的點剔除;對區域bottomRight將滿足式(1)>0,式(2)>0的點剔除。剔除后剩下的點即為手勢輪廓線外接多邊形的頂點。
手勢缺陷圖的谷底以及谷底深度的求解是建立在擬合外接多邊形基礎上,還需要對外接多邊形的每條邊所對應的輪廓線再進行一次遍歷,并將滿足以下方程的最大值求出即是該邊所對應的谷底:
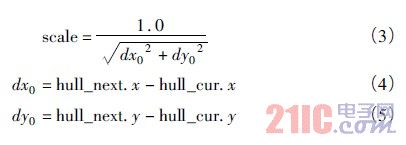

其中:scale為單位化量值;hull_cur和hull_next分別為外接多邊形當前遍歷的邊和下一條邊;dx0、dy0分別為外接多邊形當前邊的x和y坐標的差值;dx、dy分別為當前遍歷的輪廓線上的點與hull_cur點之間x和y坐標的差值;depth為遍歷點與對應邊之間的距離,它的最大值即為該邊對應的谷底深度,相應的點為谷底。
通過以上搜索可以將手勢輪廓缺陷圖的特征值找出來,接下來便可以將缺陷圖的特征值(多邊形與谷底的關系)與已建立的庫中的特征值相比較,對手勢進行匹配,將手勢輪廓缺陷圖映射到不同的手勢上去。
2.1.2手勢匹配
手勢的匹配主要是基于手勢缺陷圖的匹配,手勢缺陷圖的特征值由外接多邊形以及谷底的位置和深度組成,如圖5所示。

根據多邊形的邊數以及各條邊的程度可以確定手指的數量,而谷底的深度和位置可以確定手指的關系和位置。由于這是根據手勢的整體圖像來進行分析,所以具有一定的魯棒性,當光線變化而導致手勢圖出現差別時,并不會導致手勢缺陷圖的變化。
2.2手勢跟蹤
對于手部跟蹤,主要是基于Camshift算法實現的,它綜合利用了手勢圖像的顏色、區域和輪廓特征。Camshift是Mean.Shift算法的推廣,是一種有效的統計迭代算法,它使目標點能夠漂移到密度函數的局部最大值點。Camshift跟蹤算法是基于顏色概率模型的跟蹤方法,在建立被跟蹤目標的顏色直方圖模型后,可以將視頻圖像轉換為顏色概率分布圖,每一幀圖像中搜索窗口的位置和尺寸將會被更新,使其能夠定位跟蹤目標的中心和大小。本文中,Camshift算法被用于位置的粗定位,即確定當前手勢區域的外包矩形Rect,如圖6所示。
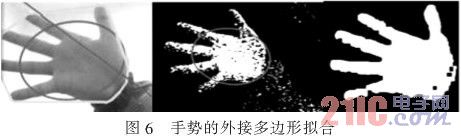
Rect將被用于前一步靜態手勢識別的輸入圖像,以便減少對圖像的分割以及模糊運算的工作量。
3手勢交互演示系統
本文在Linux系統下實現了本文提出的基于手勢輪廓缺陷圖進行手勢識別的方法,并在"嵌入式之星"開發板上實現了手勢識別的人機交互演示系統。系統處理器800MHz,存儲器RAM256MB,實時采集640×480的真彩色圖像。該系統分析攝像頭實時捕獲到的每一幀圖像,對圖片中的手勢進行實時識別。系統的應用程序是一個基于手勢識別的拼圖游戲,通過變換手勢來完成拼圖。可識別的靜態手勢狀態被分為五類:A為握拳、B為食指伸長、C為V型手勢、D為中間三指伸開、E為五指張開。A、E手型分別對應抓取與松開。手勢為握拳狀態時,手對應的圖片塊被選中(類似鼠標左鍵按下),此時可以拖動圖片,選定位置后可以換成手勢E,圖片將被松開(類似鼠標左鍵松開),B、C、D手勢分別表示將圖片放大、縮小和旋轉。
演示系統效果如圖7所示。

圖7演示系統效果
4實驗結果及分析
為了檢驗本文算法的準確性和實時性,本文在實驗室光照條件下,采集不帶任何特殊標記的手勢單目視頻圖像。實驗中參數設置如下:Camshift算法的最大迭代次數為10;手勢分割使用的HSV顏色空間如表1所示。
表1HSV顏色空間設置

對手勢二值圖像所做的數學形態學操作使用3×3的模板做開運算,使用5×5的模板做閉運算;噪聲手勢的域值設為0.01.手勢的跟蹤過程無人工干預。
表2給出了五種手勢的識別率與匹配成功率。匹配成功率是指在正確識別出手勢類型的情況下,按照2.2節給出的匹配方法將手勢輪廓缺陷圖的特征與手勢類型進行匹配的成功比率。
表2手勢識別匹配率
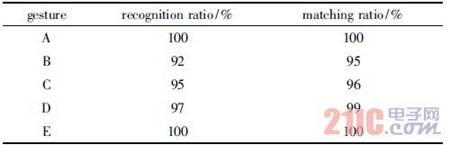
表3給出本文方法與其他方法的比較結果。與其他手勢識別方法比較,本文提出的方法有相當的識別率,還實現了手勢跟蹤的結果對識別的反饋,并在實時性方面滿足嵌入式系統的需求(20~25fps),明顯好于文獻[7](一種面向實時交互的變形手勢跟蹤方法,18fps)和目前流行的HandVu的識別效率。
表3手勢識別算法比較

魯棒性方面,由于本文采用了模糊運算,圖像模糊分割的準確率達到96.4%,對環境的變化具有很好的抗干擾性。即使背景有人的走動造成環境和光線的劇烈變化,也不會對手勢輪廓缺陷圖造成太大的影響。
5結束語
本文針對人機交互領域基于視頻手勢在嵌入式系統上的實時交互任務提出一種快速、計算量小的手勢識別方法。它結合了基于模型與基于表觀方法的特點,是建立在對目標對象-手勢的理解基礎上,通過識別靜態手勢實現了手勢的跟蹤與識別。與傳統的手勢識別系統不同,它在注重識別效果的同時還要注重算法的計算復雜度。通過使用手勢輪廓缺陷圖作為手勢識別的特征結構,不僅大大減少了計算量,由于缺陷圖是從整體結構刻畫手勢的結構,所以它還增強了手勢識別的魯棒性。實驗表明本文提出的方法可以滿足交互的實時性要求,能很好地用于手勢交互的應用系統。