
0 引言
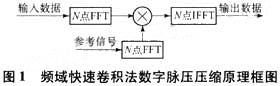
脈沖壓縮技術因解決了雷達作用距離與分辨率之間的矛盾而成為現代雷達的一種重要體制,數字LFM(線性調頻)信號脈沖壓縮就是利用數字信號處理的方法來實現雷達信號的脈沖壓縮,脈沖壓縮器的設計就是匹配濾波器的設計,脈沖壓縮過程是接收信號與發射波形的復共扼之間的相關函數,在時域實現時,等效于求接收信號與發射信號復共軛的卷積。若考慮到抑制旁瓣加窗函數,不但要增加存儲器,而且運算量將增加1倍,在頻域實現時,是接收信號的FFT值與發射波形的FFT值的復共軛相乘,然后再變換到時域而獲得的。若求N點數字信號的脈沖壓縮,頻域算法運算量大大減少,而且抑制旁瓣加窗時不需增加存儲器及運算量,相比較而言,用頻域FFT實現脈沖壓縮的方法較優,因此選用頻域方法來實現脈沖壓縮,但是仍需要做大量的運算。
1 脈沖壓縮系統工業原理
1.1 用FFT法實現LFM信號的數字脈沖壓縮
時域脈沖壓縮的過程是通過對接收信號s(t)與匹配濾波器脈沖響應求卷積的方法實現的,根據匹配濾波理論,h(t)=s*(t0-t),即匹配濾波器是輸入信號的共軛鏡像,并有相應的時移t0。則壓縮網絡的沖激響應為:
h(n)=s*(N-n
) (1)
式中:n=0,1,…,N-1;N表明當發射波形是有限寬度時,沖激響應也是一個有限序列。 根據卷積定理,并采用N點DFT,則可得壓縮網絡的輸出;
y(n)=ID{D[s(n)D[s*(N-n)]} (2)
如采用FFT算法,則可得用FFT法實現數字式脈沖壓縮的數字模型為:
y(n)=IFFT{FFT[s(n)FFT[s*(N-n)]} (3)
當N=0時,y(n)=IFFT(|FFTs(n)|2)
LFM信號的突出優點是匹配濾波器對回波信號的多普勒頻移不敏感,即使回波信號有較大的多普勒頻移,原來的匹配濾波器仍能起到脈沖壓縮的使用,這將大大簡化信號處理系統,LFM信號經匹配濾波器后的輸出脈沖y(t)具有sinc(t)函數型包絡,其最大副瓣電平為主瓣電壓的13.2dB。
頻域快速卷積法數字脈壓壓縮原理如圖1所示。
1.2 數字式LFM信號的形成
LFM信號是一種瞬時頻率隨時間呈線性變化的信號,LFM矩形脈沖信號的復數表達式為:

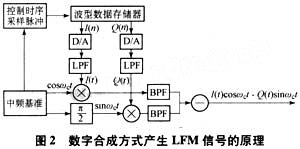
I(n)、Q(n)分別看作是匹配濾波器系數的實部和虛部,預先計算出來,存儲在存儲器中,計算時方便調用。
產生LFM信號的方法如圖2所示。
2 LFM信號實時脈沖壓縮的實現
2.1 TMS320C64x處理器特點
TMS320C64x是TI公司最新推出的高性能DSP,其時鐘頻率可達600MHz,最高處理能力為4800MIPS(百萬次指令每秒),軟件與C62X完全兼容,每個時鐘周期可以執行8條指令。TMS320C64x采用TI公司獨有的VelociTI結構,這是一種改進哈佛結構、超長指令字的CPU。這種結構使得TMS320C64x超過了傳統超標量設計CPU的性能。
TMS320C64x處理器的特點:
a)具有8個功能單元的先進的超常指令字,包括2個乘法器和6個算術單元,在統一個指令周期內可最高同時執行8條指令,是通常CPU的10倍。允許用戶開發出有效的類似于精簡指令集計算機(RISC)的代碼,以得到更高的性能。
b)指令打包,使得并行執行的8條代碼長度保持一致性,同時減小了代碼長度、取指令時間和功率消耗。
c)所有的指令都具有條件可執行的性能,從而減少了分支開銷,提高了并行運算的性能,峰值1600MIPS的指令執行速度,峰值1 GFLOPS(10億次浮點運算每秒)。
d)業界最有效的C代碼編譯器、優化器使得軟件開發有不可比擬的優越性。
e)片內64KB數據存儲器,64KB可配置為高速緩存模式的程序存儲器。統一編址的片外2GB地址空間提供對所有存 儲器類型、數據寬度的有效支持,具有無粘著的存儲器接口及各種DRAM刷新邏輯。
2.2 程序流程
脈沖壓縮實現的流程圖如圖3所示。
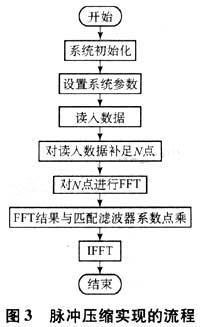
在運算過程中所有數據采用32點浮點型數據,最后脈沖壓縮的精度鋪可達10-5。其中IFFT可以完全不改變FFT程序而直接調用,IDFT如下:
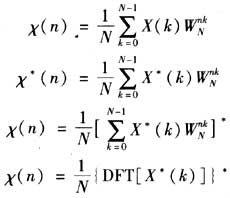
先將X(k)取共軛,直接利用FFT程序,最后將運算結果取一次共軛,以乘以1/N。
2.3 算法優化
TMS320C64x提供了
可以同時操作的8個運算單元,可以同時完成4個輸入數據的2個和、差或者完成2個32bit乘法,這對于在本系統中FFT/IFFT運算的大量蝶型運算具有很大的意義,配合硬件流水線,TMS320C64x可以不間斷的流水完成批量數據的FFT/IFFT,最好情況下單周期可以完全8次定點操作,大大降低了整個程序的時鐘周期數。
IFFT運算中第1次求共軛通過一次的算術變型在點乘的那一步就可以實現,以減少指令周期數,原理如下,設I1,Q1為接收回波數據FFT后的結果;I2,Q2為匹配濾波器求共軛后的結果,存儲在DRAM中,則有
A=(I1+JQ1)·(I2+jQ2)=I1·I2-Q1·Q2+j[I1·Q2+Q1·I2]
A*=I1·I2-Q1·Q2+j[-I1·Q2-Q1·I2]=I1·I2+Q1·(-Q2)+j[I1·(-Q2)-Q1·I2]
可得若將存儲在DRAM中的匹配濾波器求共軛后的結果(I1+jQ2)改存為(I2-jQ2)即不取共軛;在實現點乘的指令中把實部、虛部中符號變號即可。
2.4 仿真結果
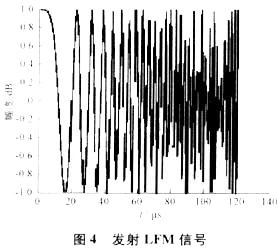
圖4所示為帶寬B=1MHz、發射脈寬t=60μs、采樣頻率fs=2MHz的LFM信號,圖5所示為該信號經脈沖壓縮后的輸出結果。
從圖5可以看出,脈壓輸出信號第1副瓣電平比主瓣低約13.2dB,壓縮信號脈寬約為t=1μs,與理論值相同。

3 結束語
由于TMS320C64x強大的并行處理能力、多處理器系統支持能力、特殊指令集、大量片上內存、極高的I/O帶寬等特性,在大數據量的實時信號處理中所體現出的優良性能,使實時脈沖壓縮的實現技術無論在速度、性能還是在電路板體積方面都有了一個飛躍的進步。