
Turbo碼雖然具有優異的譯碼性能,但是由于其譯碼復雜度高,譯碼延時大等問題,嚴重制約了Turbo碼在高速通信系統中的應用。因此,如何設計一個簡單有效的譯碼器是目前Turbo碼實用化研究的重點。本文主要介紹了短幀Turbo譯碼器的FPGA實現,并對相關參數和譯碼結構進行了描述。
1 幾種譯碼算法比較
Turbo碼常見的幾種譯碼算法中,MAP算法[1][3]具有最優的譯碼性能。但因其運算過程中有較多的乘法和指數運算,硬件實現很困難。簡化的MAP譯碼算法是LOG-MAP算法和MAX-LOG-MAP算法,它們將大量的乘法和指數運算轉化成了加減、比較運算,大幅度降低了譯碼的復雜度,便于硬件實現。簡化算法中,LOG-MAP算法性能最接近MAP算法,MAX-LOG-MAP算法次之,但由于LOG-MAP算法后面的修正項需要一個查找表,增加了存儲器的使用。所以,大多數硬件實現時,在滿足系統性能要求的情況下,MAX-LOG-MAP算法是硬件實現的首選。通過仿真發現,采用3GPP的編碼和交織方案[2],在短幀情況下,MAX-LOG-MAP算法同樣具有較好的譯碼性能。
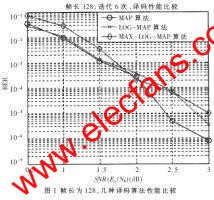
如圖1所示,幀長為128,迭代6次,BER=10-5的數量級時, MAX-LOG-MAP算法的譯碼性能比MAP算法差大約0.6dB,比LOG-MAP算法差0.2dB左右。所以,本文采用3GPP的交織和(13,15)編碼方案,MAX-LOG-MAP譯碼算法進行短幀Turbo碼譯碼器的FPGA" title="FPGA">FPGA實現與設計。
2 MAX-LOG-MAP算法
為對MAP算法進行簡化,通常將運算轉換到對數域上進行,避免了MAP算法中的指數運算,同時,乘法運算變成了加法運算,而加法運算用雅可比公式簡化成MAX*運算[4]。
將運算轉化到正對數域進行運算,則MAX*可等效為:

按照簡化公式(3)對MAP譯碼算法[1][3]的分支轉移度量、前向遞推項、后向遞推項及譯碼軟輸出進行簡化。
分支轉移度量:
為防止迭代過程中數據溢出,對前后向遞推項(5)、(6)式進行歸一化處理:


3 FPGA實現關鍵技術
3.1 數據量化
在通信系統中,譯碼器的接收數據并不是連續不變的模擬量,而是經過量化后的數字量。接收數據的量化會引入量化噪聲,從而影響譯碼的性能。所以,接收數據量化的精度直接影響到譯碼的性能。由參考文獻[5~6]可知,采用3位量化精度就能得到與沒有經過量化的浮點數據相近的譯碼性能。為了簡化FPGA的設計,本文采用了統一的定點量化標準F(9,3),即最高位為符號位,整數部分8位,小數部分3位。由此,前后遞推項(9)、(10)式的初始值可表示為:

3.2 MAX*運算單元
由前面的MAX-LOG-MAP算法介紹可知,MAX*運算單元是整個譯碼的主要運算單元,它與viterbi譯碼的ACS(加比選)運算單元一樣,先分別進行加法操作,然后對所得結果進行比較,最后將較小的一個結果作為運算結果輸出。實現結構如圖2所示。

3.3 前后向遞推運算單元
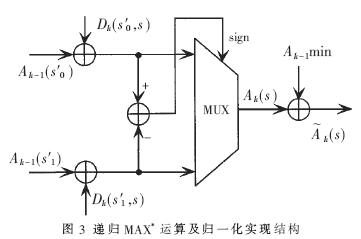
由公式(5)~(8)可知,前后向遞推單元除了需要進行MAX*與運算外,還需要進行歸一化處理。為得到較快的運算速度,首先,計算上一時刻所有狀態的最小值,然后對當前時刻的每一狀態進行MAX*運算,并將運算結果減去上一時刻的最小狀態值,即得到當前時刻遞推各狀態的歸一化值。實現結構如圖3所示。
3.4 8狀態值最小值運算單元
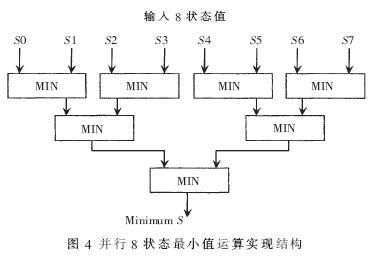
由MAX-LOG-MAP算法可知,在進行前后向遞推歸一化處理和計算譯碼軟輸出時,均需要計算每一時刻8個狀態的最小值。為了減小計算延時,采用了8狀態值并行比較的結構,與串行的8狀態值比較結構相比較,要少4級延時。實現結構如圖4所示。
4 仿真結果
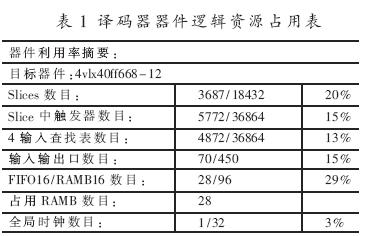
按照以上所分析的簡化譯碼算法、FPGA實現的相關參數和結構,整個譯碼采用Verilog HDL語言編程,以Xilinx ISE" title="ISE">ISE 7.1i、Modelsim SE 6.0為開發環境,選定Virtex4" title="Virtex4">Virtex4芯片xc4vlx40-12ff668進行設計與實現。整個譯碼器占用邏輯資源如表1所示。
MAX-LOG-MAP譯碼算法,幀長為128,迭代4次的情況下,MATLAB浮點算法和FPGA定點實現的譯碼性能比較如圖5所示。
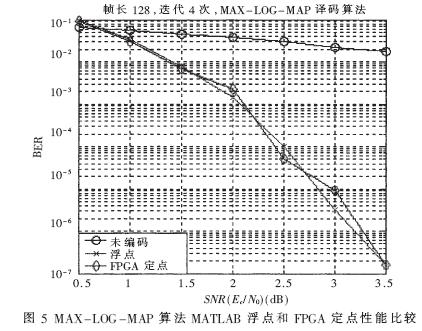
由MAX-LOG-MAP算法的MATLAB浮點與FPGA定點的性能比較仿真結果可知,采用F(9,3)的定點量化標準,FPGA定點實現譯碼性能和理論的浮點仿真性能基本相近,并具有較好的譯碼性能。
綜上所述,在短幀情況下,MAX-LOG-MAP算法具有較好的譯碼性能,相對于MAP,LOG-MAP算法具有最低的硬件實現復雜度,并且Turbo碼譯碼延時也較小。所以,在特定的短幀通信系統中,如果采用Turbo碼作為信道編碼方案,MAX-LOG-MAP譯碼算法是硬件實現的最佳選擇。